在[瞭解資料特徵]系列,我們充分理解分析類型資料的框架,以便我們在遇到不同的資料類型時能知道其賦予我們什麼限度來進行探索。在此單元中,將會更進一步的以現有的知識,開始改善我們使用的資料集。具體來說,我們將開始清理和擴充我們的資料集。通常清理的意思,指的是糾正數據文件中可識別的錯誤的過程。而擴充,是針對資料集添增或刪除表徵。與往常一樣,我們在所有這些流程中的目標是增強我們的機器學習流程。
本系列的主要主題:
本篇發文是[改善資料品質]中的第一篇,EDA。
探索式資料分析(Exploratory Data Analysis,簡稱 EDA),就是運用視覺化、基本的統計等工具,來「看」一下資料;以期進行複雜或嚴謹的分析之前,能夠對資料有更多的認識。我們在此系列當中將沿用titanic資料集。
從讀取資料集開始(由於過去章節已經進行對每個欄位的類型探索,因此此處的code也是沿用過去的章節):
import pandas as pd
import matplotlib.pyplot a plt
import seaborn as sns
%matplotlib inline
#各欄位的類型
column_types={'PassengerId':'category',
'Survived':'category',
'Pclass':int,
'Name':'category',
'Sex':'category',
'Age':float,
'SibSp':int,
'Parch':int,
'Fare':float,
'Cabin':'category',
'Embarked':'category'}
#讀取資料並且同時設置每個欄位的類型
data = pd.read_csv('data/train.csv', dtype=column_types)
注意到這次import了一個新的模組:Seaborn,它是一套建構在matplotlib之上的視覺化模組,美觀的的視覺化以及許多實用的高級呈現方式讓人愛不釋手。詳細資訊請參照官方網站。
#使用seaborn的熱度圖觀察表徵之間的線性關聯
plt.figure(figsize=(10, 8))
feature_corr = data.corr()
sns.heatmap(feature_corr, annot=True)
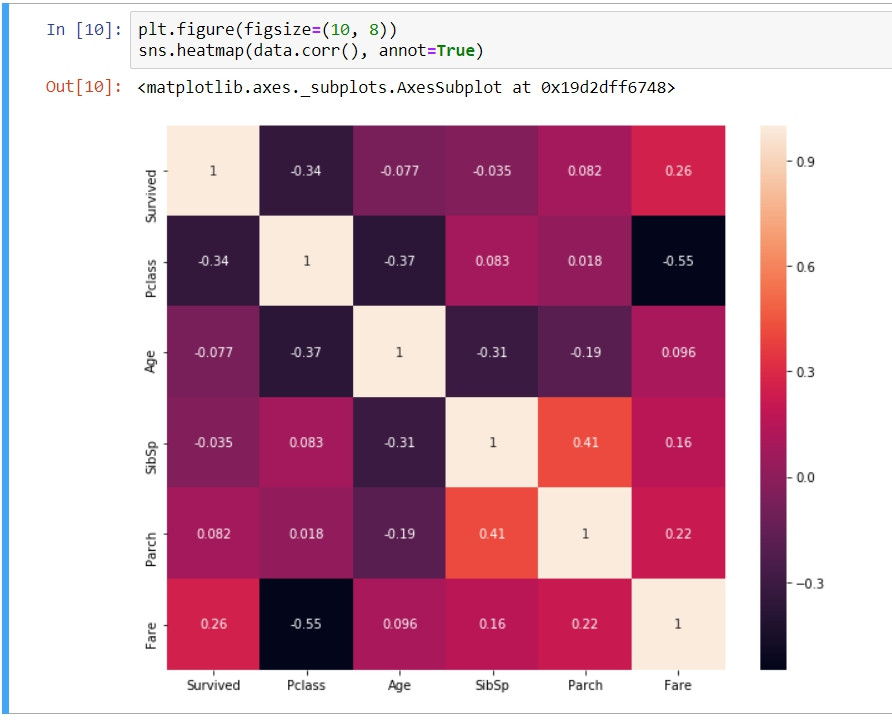
熱度圖的看法是以X軸上的表徵名稱對應到水平方向上的其他表徵名稱。例如:熱度圖的左下列,左邊第一個格子,對應的是Survived和Fare的線性關係,數字0.26代表他們的線性關係為正,也就是說票價(Fare)越高則存活(Survived)的機率也越高。我們也能觀察到所有與存活關聯的表徵最重要的是乘客等級(Pclass),為-0.34的負相關,也就是說乘客等級數字越高則存活率越低。通過前面的章節我們理解titanic資料集的所有欄位,乘客等級以數字{1, 2, 3}表現,最高等級的顧客等級為1,在其之下依次為2中等與3最低,數字越大則乘客等級越低,這點呼應到到顧客的等級數字與生存的機率為負相關。
#各Pclass對應的生存率
sns.barplot('Pclass','Survived', data=data)
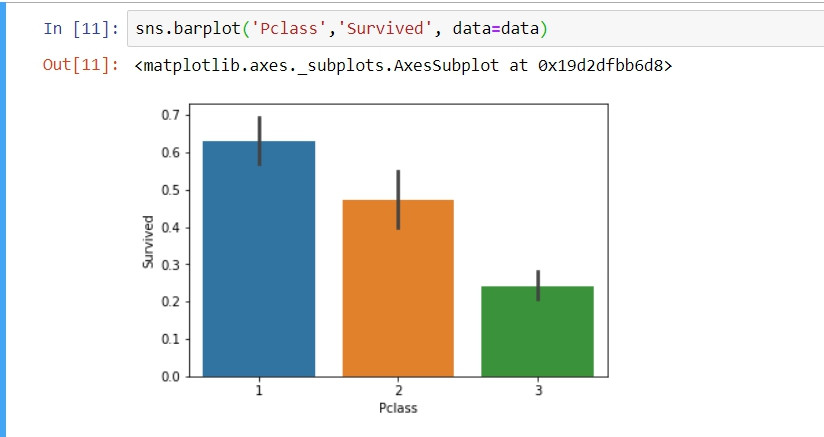
由於我們的corr關聯矩陣是由數字類型的表徵所構成的,所以其他類型的表徵都沒有在此關聯矩陣當中。我們需要對例如category這樣類型的表徵單獨做視覺化:
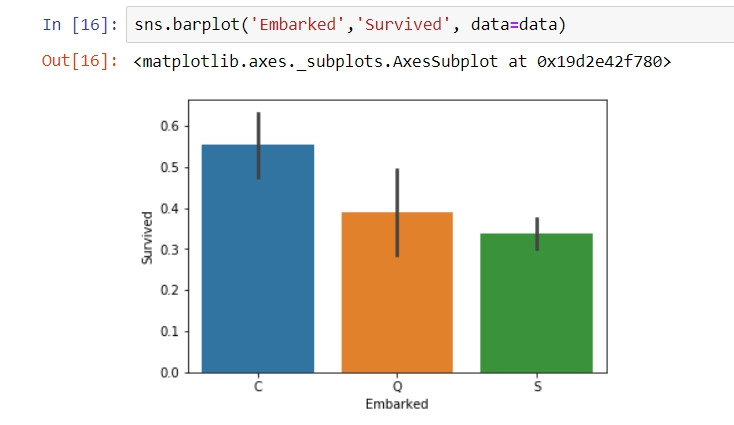
#各港口上船的乘客對應的生存率
sns.barplot('Embarked','Survived', data=data)
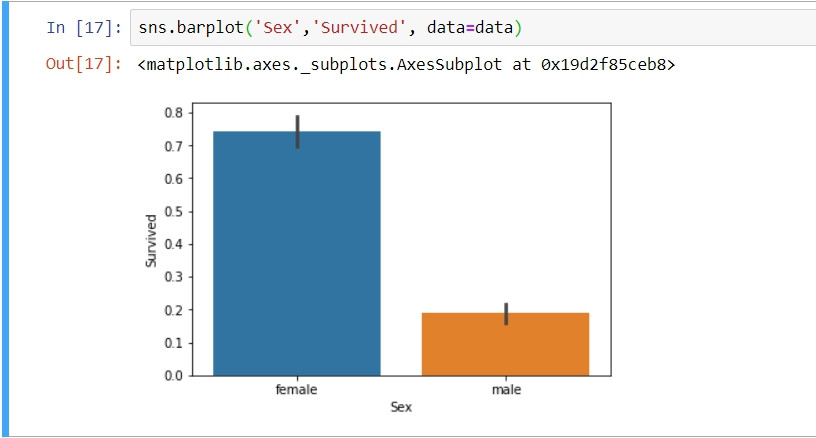
#性別對應的生存率
sns.barplot('Sex','Survived', data=data)
#比對生存以及死亡的乘客在各表徵的數量
for col in ['Pclass', 'SibSp', 'Parch', 'Fare']:
fig = plt.figure(figsize=(12,6),)
sns.distplot(data[data.Survived == 0][col],
bins=10,
color='gray',
label='not survived',
kde=True)
sns.distplot(data[data.Survived == 1][col],
bins=10,
color='orange',
label='survived',
kde=True)
plt.title('Passenger {} Distribution - Survived vs Non-Survived'.format(col), fontsize = 15)
plt.ylabel("Frequency of Passenger Survived", fontsize = 15)
plt.xlabel("Passenger Class", fontsize = 15)
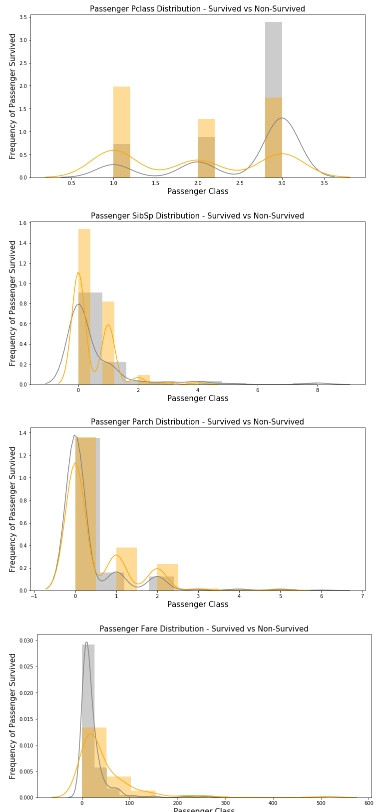
透過EDA,我們很快觀察到資料集中與乘客存活率相關聯的重要表徵,例如:乘客等級越高的生存率相對較高、女生存活機率遠高於男性、從C港口上船的旅客有較高的存活率...等等。有了這些觀點會影響往後的資料清洗以及擴充流程。

